Section E.1 Monoalphabetic Analysis
Let us see if we can determine what is happening in this message:
VGH THT CMY HOG CRC BWT HMF AJC UZN RBY HOG CRV GHT YHO GCR ZNR JTS WUD HRT VZR HVH MFN WVA JCU ZNR BBC KCV HMF AMU BWO KHY AVC KCV VCR TAM BVG CMZ RHV HMF BNZ MVG CRC TVN DVG CAK OGA SCV HMN RBC RVG HTA RRA MFC LCM VND VGC AKO GAS CVV GCM DNR LTU NWR YHO GCR AKO GAS CVV GHT YHO GCR AMB VGC NVG CRL NMN AKO GAS CVH YYH OGC RTZ CZH KKT VWB UGA TAT VRW YVW RCV GAV ZCY AMC QOK NHV VNY RAY JHV AMB DHF WRC NWV VGC LCT TAF CGN ZCX CRV GHT HTM NVH MFC MCR AKV RWC VGC RCA RCV CYG MHY AKK UVZ CMV UTH QDA YVN RHA KBH DDC RCM VLN MNA KOG ASC VHY TWS TVH VWV HNM YHO GCR TAM BBC OCM BHM FNM GNZ VGC UAR CWT CBV GCU YNW KBS CLA BCW MSR CAJ ASK CHM FCM CRA KGN ZCX CRL NMN AKO GAS CVH YYH OGC RTY AMS CYR AYJ CBZ HVG TNL CTH LOK CAM BXC RUN KBV CYG MHP WCT HMO ARV HYW KAR ZHV GVG CWT CND DRC PWC MYU AMA KUT HTH TNW RDH RTV VNN K
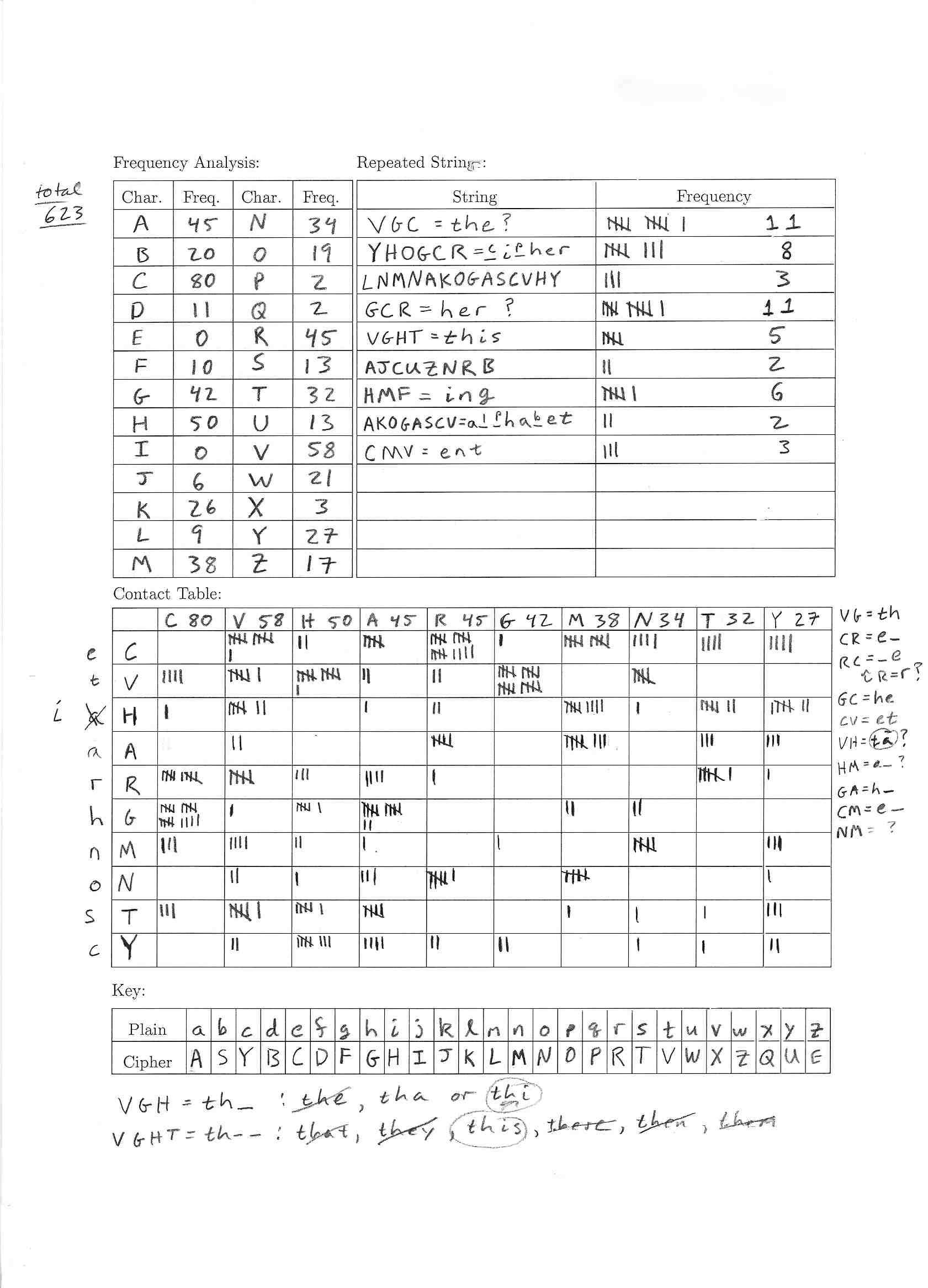
We begin with a basic frequency analysis (see Figure E.1.1 and Figure E.1.2 ), counting how many times each character appears, and find that "C", "V", and "H" are most common. This leads us to guess that C=e, V=t, and H=a since "e", "t", and "a" are the three most common letters in English.
Next we look for repeated strings of characters. We find, among others, that "VGC" appeared very frequently. Based on what we did before this would be "t_e" and so it appears that G=h.
The next step is a bigram analysis, that is we look at two letter combinations. We find that "CR"="e_" and "RC"="_e" are very common and comparing this to a table of common bigrams we guess that R=r.
We also find that "VH" which is "ta" was more common than it should be and thus one of our previous letter assignments is perhaps wrong. Going back to our repeated strings we find "VGHT" in a couple of places and when we look at common words starting with "th" that could match "VGHT" the only one that really works is "this." Therefore H\(\neq\)a, H=i, and T=s.
Finally, the digraph "CM"="e_" is very frequent so should represent either "er" or "en." Since, "er"="CR" we conclude that M=n
Going back to repeated strings we find that "HMF"="in_" appears in a number of places and so it is likely that F=g. Finally, we know "a" should be represented by a common letter and the only really common cipher letter that is not used is "A" so A=a.
At this point we have nine possible substitutions, C=e, V=t, G=h, R=r, H=i, T=s, M=n, F=g, and A=a, which we have some confidence in. Now we need to write out lines of the message filling in what we have and looking for words we can recognize. As a result we find:
- ZRHVHMG = _riting so we get Z=w
- AMB = an_ and is a common trigraph so B=d
- WTHMF = _sing and BWOKHYAVC = d_pli_ate so we get W=u and Y=c
- KCVVCR = _etter so K=l
- AKOGASCV = al_ha_et and YHOGCR = ci_her so O=p and S=b
- ZNRB = w_rd so N=o
- ARRAMFCLCMV = arrange_ent so L=m
- ND = o_ and DNRLT = _orms so D=f
- AMU = an_ and UNWR = _our and TVWBU = stud_ so U=y
- JCU = _ey and YRAYJ = crac_ and ZNRJ = wor_ so J=k
- CQOKNHV = e_ploit so Q=x
Now the only letters left to figure out are "P" and "X." Looking for "P's" we see that there are only two and they are both followed by "W"="u," so it looks like P=q and this is confirmed by DRCPWCMYU = frequency. Then scanning through what we have for a message we see XCRU = _ery and thus X=v fills in our last unknown letter very nicely.
Final Deciphered Message:
"This is enciphered using a keyword cipher. This cipher works buy first writing out a key word, deleting any duplicate letters, and then writing down the rest of the alphabet in order. This arrangement of the alphabet then forms your cipher alphabet. This cipher and the other monoalphabetic ciphers we will study has a structure that we can exploit to crack it and figure out the message. However this is not in general true. There are technically twenty six factorial different monoalphabetic substitution ciphers and depending on how they are used they could be made unbreakable. In general however monoalphabetic ciphers can be cracked with some simple and very old techniques, in particular with the use of frequency analysis is our first tool."